1. Introduction
Content moderation has evolved rapidly from simple RegEx keyword matching to context-aware Artificial Intelligence. Today’s engineers face a difficult choice regarding infrastructure: Cloud-based Large Language Models (LLMs), like those on AWS Bedrock, offer state-of-the-art reasoning but introduce latency and variable costs. Conversely, “local” LLMs (like running Llama 3 on own-hosted infrastructure) offer privacy and predictable pricing but require significant effort to maintain reliability.
This article details the technical architecture of a Hybrid Moderation Checker. We will demonstrate a modular “Agent/Tool” pattern designed to route requests intelligently between AWS Bedrock and self-hosted local inference servers.
Beyond the immediate implementation, we will explore the critical steps required to take this system to production—including security and observability—and conclude with a look at how emerging multimodal models like AWS Nova are fundamentally simplifying the future of Trust & Safety architectures.
2. System Architecture Overview
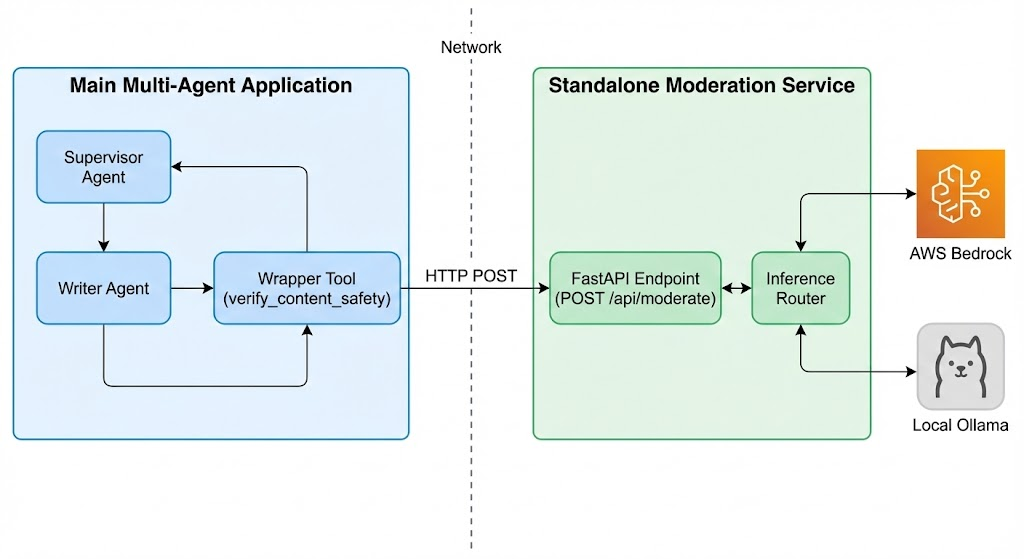
A robust AI application must separate its core logic from its serving layer. This application is designed around a portable Agent-Tool core. Below is a high-level view of how this standalone service can be integrated via a microservice pattern, keeping the main application decoupled from the moderation specifics.
The Technical Stack
- The Demonstration Layer (FastAPI & Uvicorn): Serves as a simple HTTP interface to interact with the agent (as seen in the “Standalone Moderation Service” box above). In a production environment, this layer could easily be replaced by AWS Lambda functions or containerized services on Amazon ECS/EKS.
- The Portable Logic Layer (The Core): We utilize the
strands-agentsSDK to implement a portable@toolfor moderation. This is where the actual business logic and the “Inference Router” reside, independent of the framework serving it. - LLM Orchestration: AWS SDK for Python (Boto3) for cloud inference and direct REST API calls for local inference (e.g., an Ollama server).
- Resilience Utilities: Custom implementations for configurable timeouts and polymorphic JSON parsing to handle LLM unpredictability.
3. Deep Dive: The Hybrid Inference Router & Resilience
The heart of the application is the routing function—a traffic controller that dispatches payloads based on availability, policy, or cost preference. Building this requires overcoming specific practical challenges.
3.1. Handling Local Inference Timeouts
Self-hosted inference on CPUs or consumer-grade GPUs is significantly slower than cloud APIs, especially when processing large “batch” inputs (e.g., a text file with 500 comments). Standard HTTP timeouts (often defaulting to 30-60 seconds) will frequently result in ReadTimedOut errors. A production-grade system must implement configurable, extended timeouts—in our reference implementation, defaulting to 300 seconds (5 minutes)—to handle heavy local processing loads gracefully.
3.2. Robust Data Processing: The “Batch List” Problem
A major hurdle in getting LLMs into production is ensuring a consistent output schema. Your API expects a single JSON dictionary response. However, when a user uploads a multi-line file, an LLM trying to be “helpful” often returns a JSON List of results instead.
A brittle system crashes here. A resilient system uses a polymorphic parsing utility. Our implementation detects if the output is a list, and if so, automatically summarizes it into a single, API-compatible dictionary. This ensures the application never crashes due to simple schema mismatches.
4. Production Readiness: Security and Observability
Moving from a proof-of-concept to a production environment requires addressing critical operational requirements. A hybrid architecture introduces unique surface areas for both security and monitoring.
4.1. Hybrid Security Posture
Security must be managed across two distinct environments:
- Cloud Security (AWS): Adhere to the principle of least privilege. The application should utilize IAM Roles (e.g., IAM Roles for Service Accounts if running on EKS) with precisely scoped permissions to invoke only the specific Bedrock models required. Avoid embedding long-term credentials in code.
- “Local” Security: In a production context, “local” rarely means a laptop; it means self-managed EC2 instances with GPUs or on-premise servers. This infrastructure must be secured with strict network isolation (VPCs, Security Groups) and require mutual TLS (mTLS) authentication for any inbound API requests to prevent unauthorized access to the inference server.
4.2. Hybrid Observability
In a hybrid system, when a request fails, you must instantly know where it failed. Did the local server time out, or did the AWS API throttle the request?
Production implementations must emit structured logs and metrics—ideally sent to a centralized system like Amazon CloudWatch. Crucially, every log entry should be tagged by its provider dimension (provider: aws vs. provider: local). This allows operators to build dashboards monitoring latency, error rates, and costs distinct to each infrastructure path.
5. Extensibility and the Multimodal Future with AWS Nova
A robust enterprise system must evolve. While initial implementations often focus on text, a complete Trust & Safety platform must handle images, video, and audio.
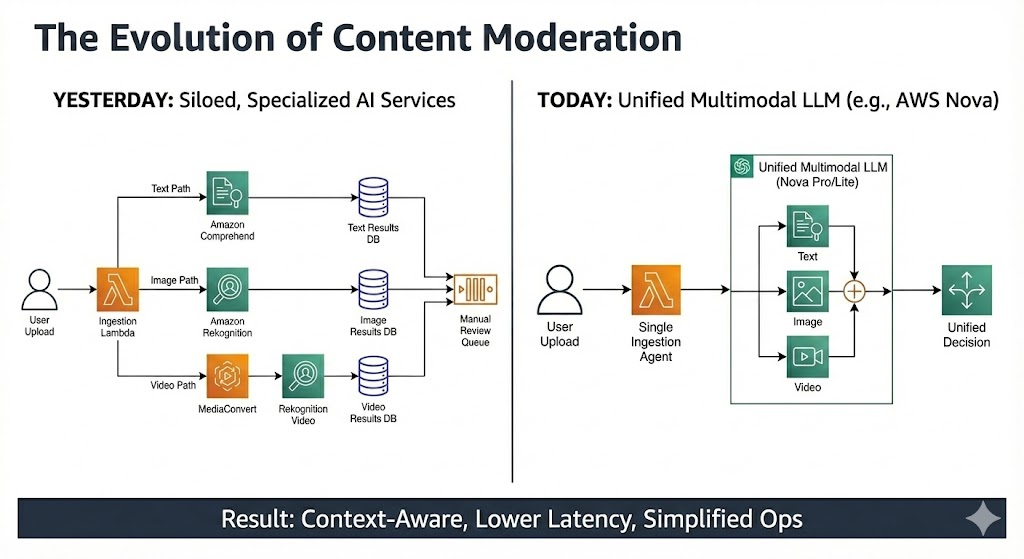
The “Pre-Nova” Architectural Complexity
Until recently, extending a moderation system to be multimodal required building a complex web of specialized agents. You needed a Supervisor agent routing content to an “Image Agent” (wrapping Amazon Rekognition), a “Video Agent” (wrapping AWS Elemental MediaConvert + Rekognition Video), and a “Text Agent” (wrapping Amazon Comprehend or Bedrock). This resulted in high architectural overhead, increased latency, and complex cost management.
The “Post-Nova” Architectural Simplification
The release of foundation models like AWS Nova on Amazon Bedrock has dramatically simplified this landscape. Models like Nova Pro are natively multimodal—they can accept text, images, and video simultaneously in a single prompt and perform complex reasoning across them.
This shift allows us to collapse complex multi-agent webs into streamlined, unified architectures, as shown below:
Architectural Impact:
As illustrated above, the future architecture is radically simplified:
- A Supervisor Agent receives content of any type.
- It routes directly to a single Unified Multimodal Core.
- This core invokes an AWS Nova model, passing the policy, text, and media in one call.
- A unified, context-aware decision is returned.
Architectural Note on Video: While models like Nova can process raw video, production architects must still consider cost and latency. For long-form video content, it remains a best practice to optimize architectures by using a lightweight sampler to extract keyframes for submission to the LLM, rather than sending massive raw video files for every request.
6. Conclusion
Building production-ready AI tools requires navigating the tension between cutting-edge capabilities and operational reality. By mastering core concepts like resilient hybrid routing, robust data parsing, and rigorous security observability, engineers can build stable platforms today. Furthermore, by understanding the shift towards multimodal models like AWS Nova, teams can prepare for a future where architectural complexity decreases even as AI capabilities grow.