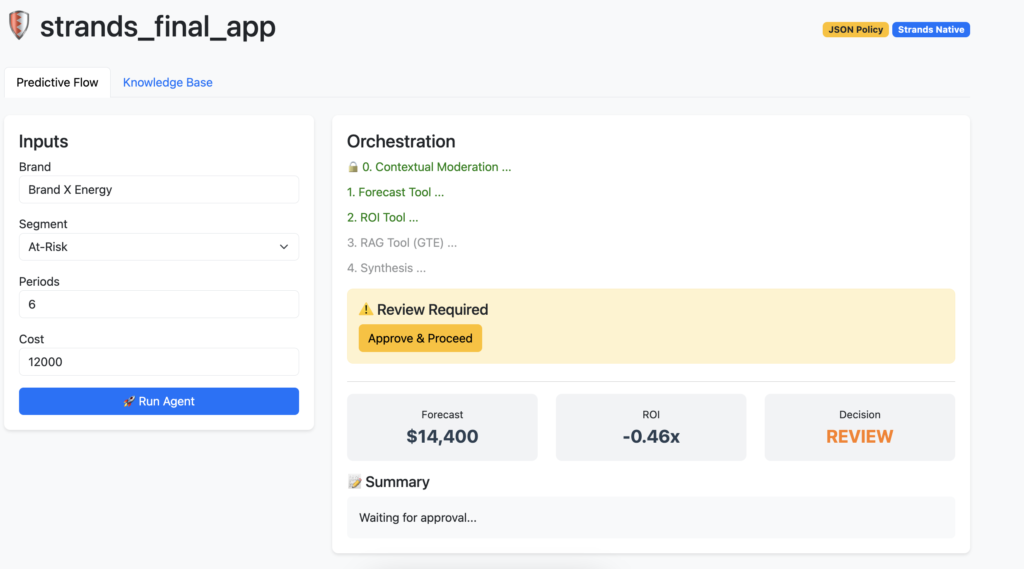
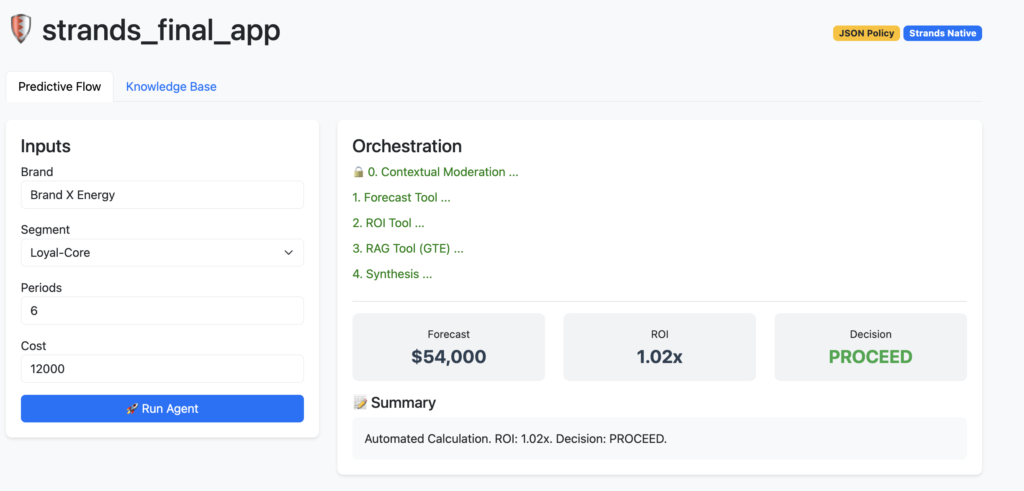
This application is a specialized multi-agent system designed to provide predictive financial insights (revenue forecasting and ROI analysis) with integrated strategic context via Retrieval-Augmented Generation (RAG).
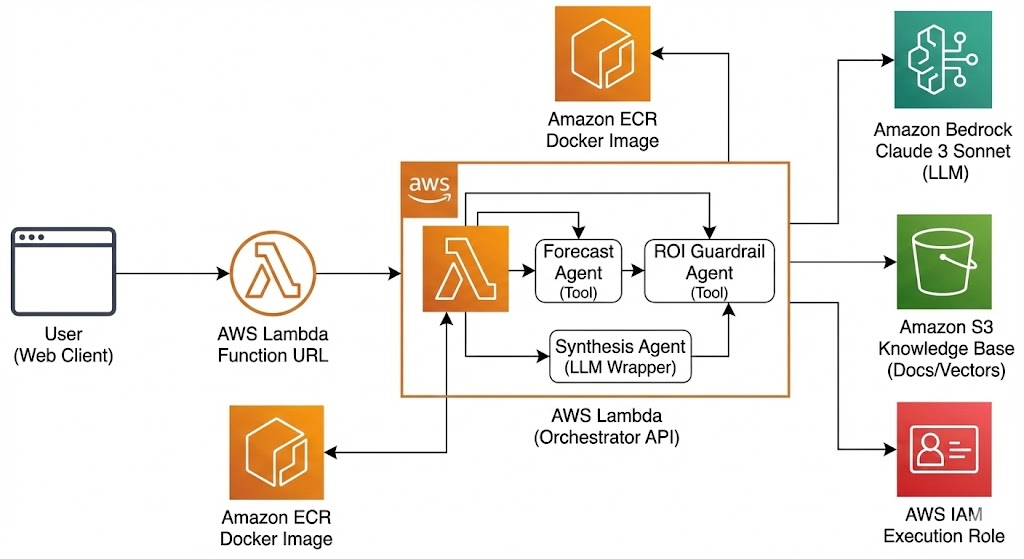
The system is generated by a scaffolding script (setup_generator.sh) that establishes a standardized, secure, and deployable architecture. Key features include:
- Embedded “Strands” Core: A lightweight, local Python abstraction layer for orchestrating AWS Bedrock models (specifically Claude 3 Sonnet) and managing deterministic tool execution.
- Guardrails-First Approach: Integrated Contextual Moderation to pre-screen inputs against safety policies, and business logic guardrails to flag high-risk financial scenarios.
- Multi-Format Local RAG: A built-in knowledge base using ChromaDB to ingest and retrieve context from PDF, CSV, and TXT documents.
- Serverless-Ready: Packaged via Docker with the AWS Lambda Web Adapter for seamless deployment to AWS Lambda or AWS App Runner.
2. System Architecture
The application follows a layered architecture, processing requests sequentially through safety checks before engaging orchestration logic.
High-Level Request Flow
- Client Layer: A Bootstrap-based frontend (
index.html) collects user inputs or file uploads. - API Layer (FastAPI): Receives requests.
- Security Layer (Guardrail): The input is passed to the Moderation Agent to validate against safety policies. If unsafe, execution stops immediately.
- Orchestration Layer (Strands Core): If safe, the Workflow Agent receives the input. It executes deterministic tools first, then uses the Strands Core to synthesize results via Bedrock.
- Data Layer (Tools & RAG): Tools perform mathematical calculations or query the ChromaDB vector store for context.
- Infrastructure: The entire stack runs within a Docker container optimized for AWS Lambda.
3. Key Technologies & Components
| Component | Technology | Description |
| API Framework | FastAPI / Uvicorn | High-performance asynchronous Python web framework. |
| LLM Provider | AWS Bedrock | Provides access to Anthropic Claude 3 Sonnet models. |
| Orchestration | Local “Strands” Core | Custom embedded Python layer (src/strands/) for agentic control flow and JSON enforcement. |
| Vector Store | ChromaDB | Local, persistent vector database for RAG operations. |
| Embeddings | SentenceTransformers | Uses BAAI/bge-small-en-v1.5 for semantic text embedding. |
| Document Processing | pypdf, pandas | Extracts text from PDF and CSV documents for ingestion. |
| Runtime Adapter | AWS Lambda Web Adapter | Allows standard web apps to run on AWS Lambda functions. |
4. Core Implementations
4.1 The Embedded “Strands” Core (src/strands/core.py)
The generator addresses stability by embedding a lightweight orchestration layer directly into the project, rather than relying on external, potentially unstable SDK packages.
@tooldecorator: A simple passthrough decorator used to register functions as available capabilities for the agent.Agentclass: A wrapper around theboto3Bedrock runtime client. It manages:- Injecting system prompts that define the agent’s persona.
- Enforcing strict JSON output formats via prompt engineering.
- Handling the Bedrock invocation lifecycle.
extract_json(text): A robust utility using regular expressions to locate and parse JSON blocks embedded within potential markdown chatter from the LLM, ensuring reliable structured output.
4.2 The Agents
Contextual Moderation Agent (src/agents/moderation.py)
This agent acts as a pre-execution firewall. It loads rules from config/moderation_policy.json and uses Bedrock to evaluate incoming strings against these rules. It outputs a structured verdict: {"safe": bool, "reason": str}.
Predictive Workflow Agent (src/agents/workflow.py)
This is the primary business orchestrator. It utilizes a hybrid execution model for reliability:
- Deterministic Phase: Tools for math (
forecast_revenue,analyze_finance) and search (consult_knowledge_base) are executed Pythonically before invoking the LLM. This ensures calculations are accurate and not hallucinated. - Synthesis Phase: The outputs of these tools are passed as context to the Strands
Agent(Claude 3). The LLM’s only role is to synthesize the pre-calculated data into a coherent narrative and format the final JSON response.
4.3 Local RAG Engine
The application includes a self-contained RAG stack located in src/core/engine.py and src/api/main.py.
- Ingestion (
/upload_kb):- Detects file type (PDF, CSV, or TXT/MD).
- Extracts raw text using appropriate libraries (
pypdforpandas). - Guardrail: Passes extracted text to the Moderation Agent. Unsafe content is rejected before indexing.
- Chunks text into 1000-character segments.
- Embeds chunks using the local
sentence-transformersmodel. - Stores vectors in persistent local ChromaDB (
/tmp/chroma_db_local).
- Retrieval: The
consult_knowledge_basetool queries ChromaDB for the top-1 most relevant semantic match to provide context to the forecast.
5. Guardrails and Safety Mechanisms
The architecture implements defense-in-depth through multiple guardrail types:
- Input Safety Guardrail (AI-based):
- Implemented in the API layer before workflow execution.
- Uses the Moderation Agent to block PII, aggressive language, or off-topic requests defined in the JSON policy.
- Business Logic Guardrail (Deterministic):
- Implemented in the
analyze_financetool. - Calculates ROI mathematically. If the ROI is below the configured threshold (default 0.5), the tool sets the decision flag to “REVIEW”.
- The API response forces a “Human-in-the-Loop” UI state unless a
force_approvaloverride flag is sent.
- Implemented in the
- Output Format Guardrail (Regex-based):
- Implemented in
src/strands/core.py. - Ensures that despite LLM verbosity, only valid, parsable JSON is returned to the API, preventing downstream application errors.
- Implemented in
6. Deployment and Infrastructure
The generator creates a Dockerfile optimized for serverless deployment.
- Base Image:
python:3.11-slimfor minimal footprint. - Lambda Adapter: Includes
aws-lambda-adapter:0.8.1. This extension intercepts Lambda events and converts them to standard HTTP requests for FastAPI, allowing the container to run interchangeably on Lambda or standard container platforms (Fargate, App Runner, local Docker). - Optimization: PyTorch is installed with CPU-only binaries to reduce image size. The embedding model is pre-downloaded during the build phase to improve cold-start performance.
- Configuration: The application is configured via environment variables set in the Dockerfile (
PORT=8080,AWS_LWA_ASYNC_INIT=true).
Screenshots