We are transitioning our video analysis from a manual, labor-intensive process to an automated intelligence system. This brief explains the technology behind this shift—specifically “Agentic AI”—and why it matters for our organization’s efficiency and competitive edge.
1. The Core Concept: What is “Agentic AI”?
Most people know AI as a chatbot: you ask a question, and it gives an answer. Agentic AI is different. It is more like hiring a digital employee than using a search engine.
Think of it like the difference between a library and a research assistant:
- Standard AI (The Library): You have to look up the information yourself. You ask, “Show me all the passes,” and it lists them. You still have to do the work to find the meaningful ones.
- Agentic AI (The Assistant): You give it a goal, like “Find me examples where our defense broke down,” and it figures out how to do the work. It watches the video, identifies the defensive lines, filters out the noise, and presents you with a finished report.
In our platform, we use two types of these “digital assistants”:
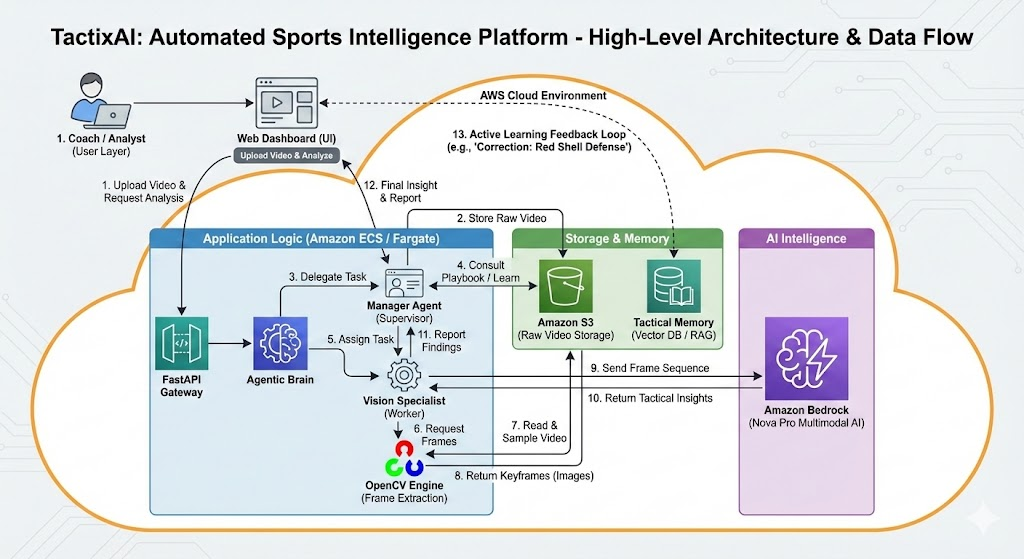
The “Manager” (Supervisor Agent)
- Role: This agent acts like a project manager. It doesn’t watch the video itself. Instead, it listens to the coach’s request (e.g., “Analyze the counter-attacks”).
- Action: It breaks that big request into smaller tasks and assigns them to the specialist. It ensures the job gets done correctly and summarizes the final results for the coach.
The “Specialist” (Video Agent)
- Role: This agent is the worker bee. It has the specialized tools to actually “watch” the video frames.
- Action: It scans the footage, identifies players, tracks the ball, and reports back to the Manager with the raw data (e.g., “I saw a turnover at minute 14:00”).
2. How It “Watches” the Game (The Vision Engine)
We don’t just dump a massive video file into a black box. The system uses a smart, cost-effective process to “see” the game, much like a human scout would.
- Snapshotting: Instead of processing every single millisecond of video (which is expensive and slow), the system takes “snapshots” of the game every second or so. It creates a digital flipbook of the match.
- Contextual Understanding: It doesn’t just look for objects (like “a ball” or “a shoe”). It looks for context. It understands that a group of players standing in a line is a “defensive wall,” or that a player running into open space is a “threat.”
- Result: This allows the system to tell you why a play happened, not just that it happened.
3. Why It Gets Smarter (Active Learning)
One of the biggest frustrations with software is that it doesn’t know our specific way of doing things. This platform solves that with Active Learning.
- The “Coach’s Correction”: Imagine the AI labels a play as a “Low Block,” but your Head Coach calls that specific formation a “Red Shell.”
- The Learning Loop: The coach can type a simple correction: “Actually, we call this a Red Shell.”
- The Memory: The system saves this correction forever. Next time it sees that formation, it will correctly identify it as a “Red Shell.” It effectively “interns” with your coaching staff, learning your specific playbook and terminology over time.
Summary of Business Value
| Feature | The Old Way | The Agentic AI Way | Business Benefit |
| Workflow | Manual: Analysts spend hours tagging every pass and tackle by hand. | Automated: The “Manager Agent” handles the tagging instantly. | Speed: We get halftime-level insights in minutes, not hours. |
| Intelligence | Stats: “Player X ran 10km.” | Insight: “Player X ran into space to create a goal.” | Quality: We move from counting numbers to understanding strategy. |
| Knowledge | Lost: When an analyst leaves, their knowledge leaves with them. | Retained: The system learns and remembers our playbook forever. | Consistency: Institutional knowledge is captured in the software. |
Export to Sheets
The diagram below visualizes the high-level architecture and data flow described in this article.