Refer to my pervious article – Processing GLIEF data in JSON format . I wanted refresh my knowledge of Pentaho Data Integration tool and see if I could process huge XML file without running into Java OOM (Java Out of Memory) problem.
Pentaho offers Input step called – XML Input Stream (StAX – Streaming API for XML), which can be used to parse large XML file iteratively. I used this example at – Parsing Huge XML Files in Pentaho Kettle to read and process Gleif XML datasets.
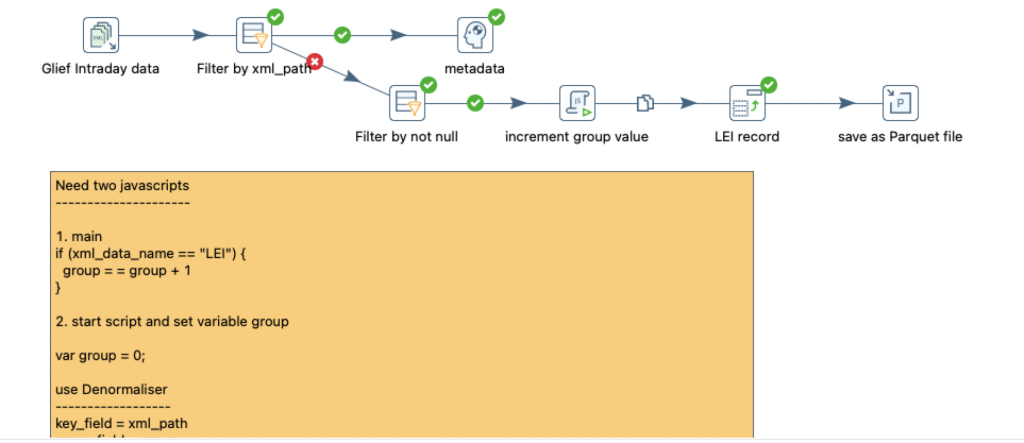
Tasks
- Read XML file
- Filter not null values i.e. xml_data_value IS NOT NULL
- Transform using JavaScript – increment group variable – using first attribute in a record (make sure it is unique) – in our case it is LEI
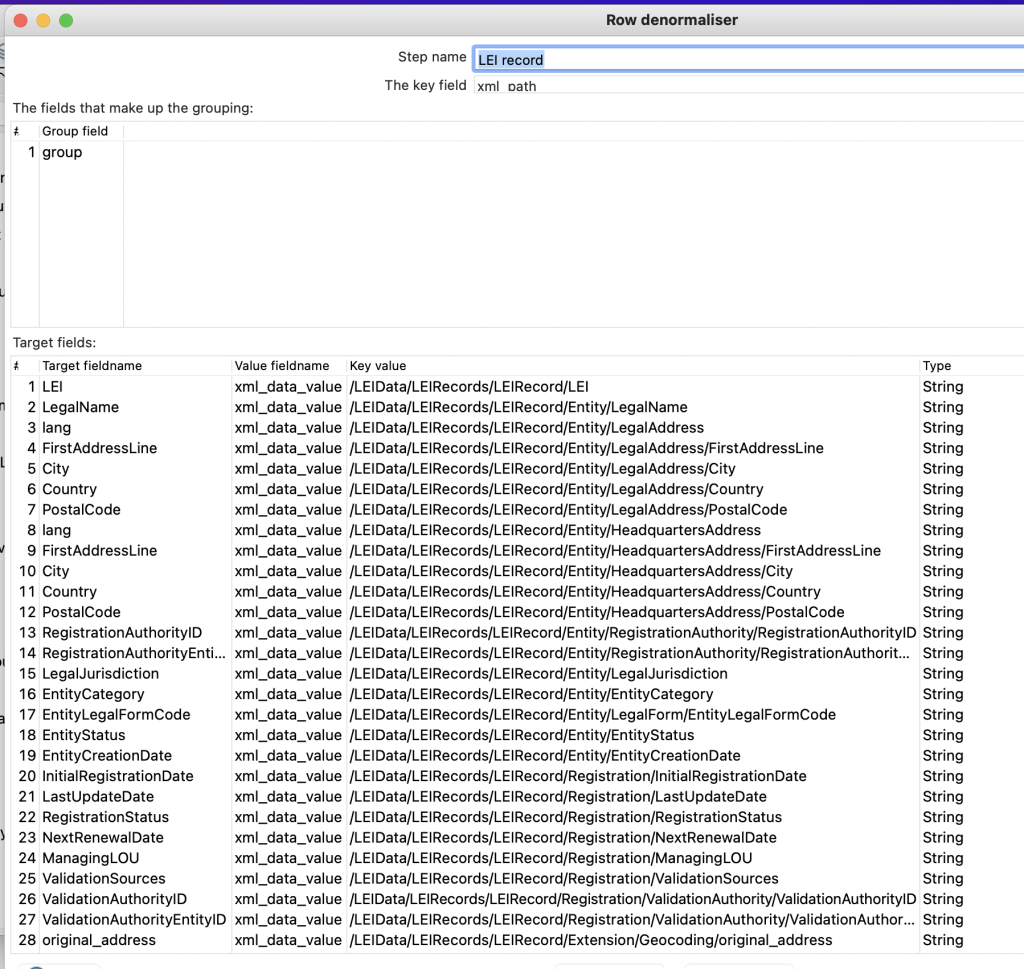
- Use group variable in Row denormaliser step to combines data from several rows into one row by creating new Target columns/fields
- Save data as parquet file
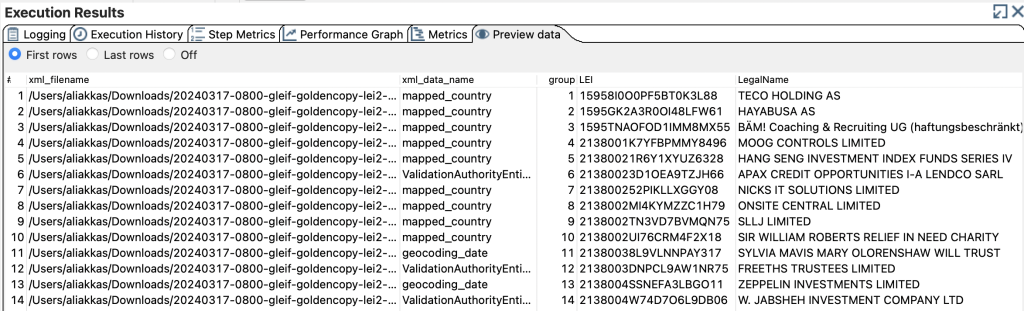
Validating Parquet output file
I used DuckDB in Google CoLab to verify the result. DuckDB provides support for both reading and writing Parquet (a columnar based file format that is efficient for storage and querying data).
import duckdb
conn = duckdb.connect()
results = conn.execute('''
SELECT *
FROM read_parquet('/content/drive/MyDrive/data/glief.parquet20240319.parquet')
''').df()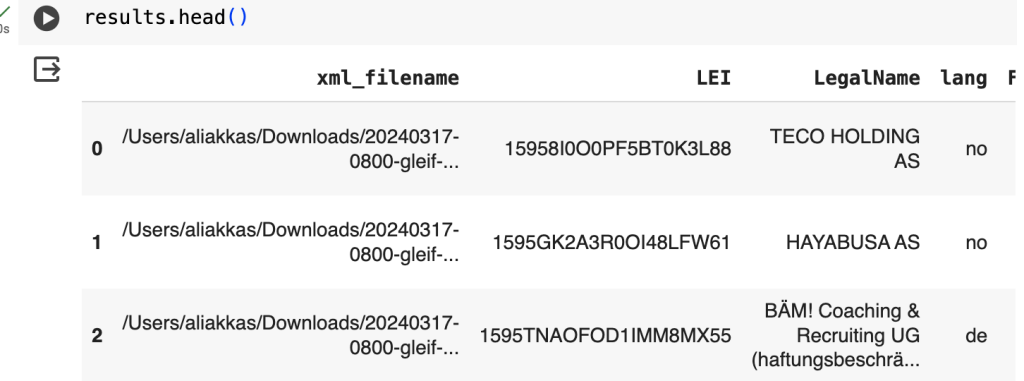
Using Apache Hop
“The Hop Orchestration Platform, or Apache Hop, aims to facilitate all aspects of data and metadata orchestration.”
https://hop.apache.org/
It was a surprisingly easy task to import Pentaho transformation into Apache Hop using importer tool which comes with it.
Hop could not recognise the Parquet Output step and needed to use Hop’s Parquet Output File step.
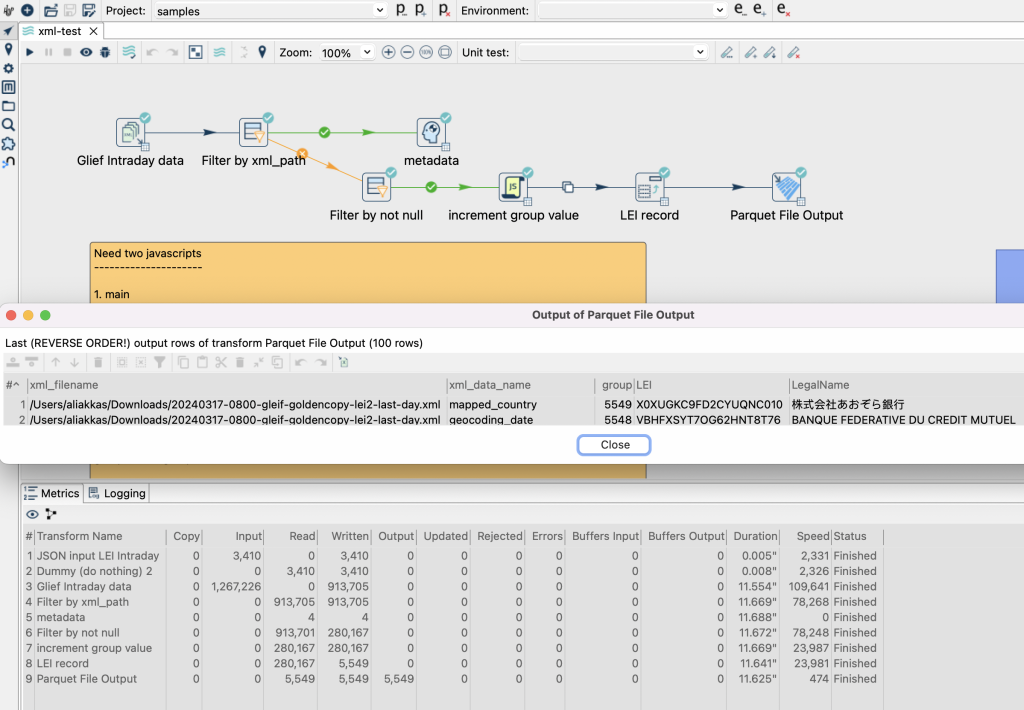
Running Hop in Google Colab
It is possible to run Hop on Google CoLab. You just need to download Hop runtime and run hop-run.sh.
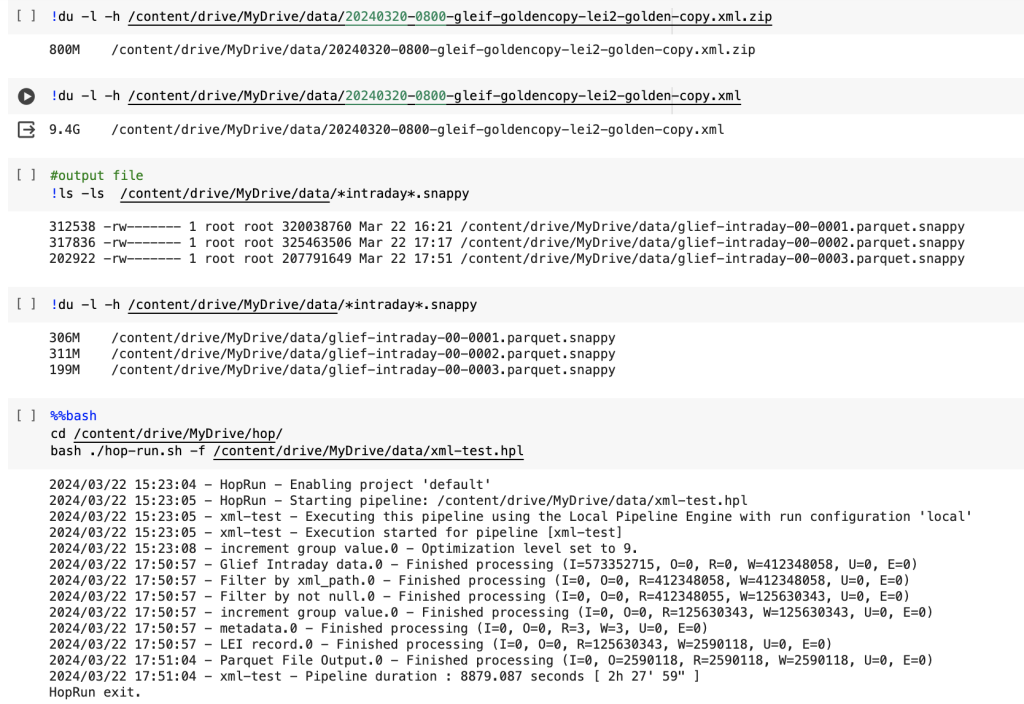
%%bash
#I copied Hop into Gdrive
cd /content/drive/MyDrive/hop/
bash ./hop-run.sh -f /content/drive/MyDrive/data/xml-test.hplLast thoughts
Apache Hop (created from forked Kettle source codes) or Pentaho is a great tool for working with small datasets (<= 2 Gb for better performance) and easy to create ETL pipelines using drag and drop features of the tool (hop-gui.sh). Apache Hop offers more and also can run ETL pipelines on different engines – Local and Spark, Flink & Dataproc using Apache Beam.
Pentaho/Kettle has been around for a long time and many small, medium and large corporations are using it for their data integration and ETL capabilities.
I would recommend Apache Hop instead of Pentaho/Kettle. However for processing large data engineering tasks use serverless ETL tools such AWS Glue, Google Dataproc. For processing large datasets, one should consider using engine like Apache Spark, Apache Flink, Trino.
Leave a Reply