In this article, I will share my approach (see my previous article for further information on data validation) for carrying out data validation check using streaming data from a Kafka topic.
Checking data is very important. Many often this task is get overlooked. One cannot trust source data, especially if you are ingesting data for deriving business insights. Quality data is a prerequisite to build trust in your data.
Handling errors and warnings using Apache Spark
A number of checks can be performed after ingesting data:
- check_date_range
- check_date
- check_integer
- check_numeric
- check_positive_number
- check_specific_values (missing values)
- check_regex
- check_not_null
- check_not_blank
- check_postcode
- check_duplicates
The business may requires that certain checks must be written out as errors or warnings depending on needs. Apache Spark allows you to accomplish these by using dataframe. Same techniques can be applied to streaming data (bounded data – small batches).
Validation Requirements
The basic ask is to write out errors and warnings in two extra fields in your dataframe. One field for warning and other for capturing error. Each different error/warning should be given a reference code i.e check_not_null or some tag number. The log should include a count of how many of each error/warning code raised.
Use case
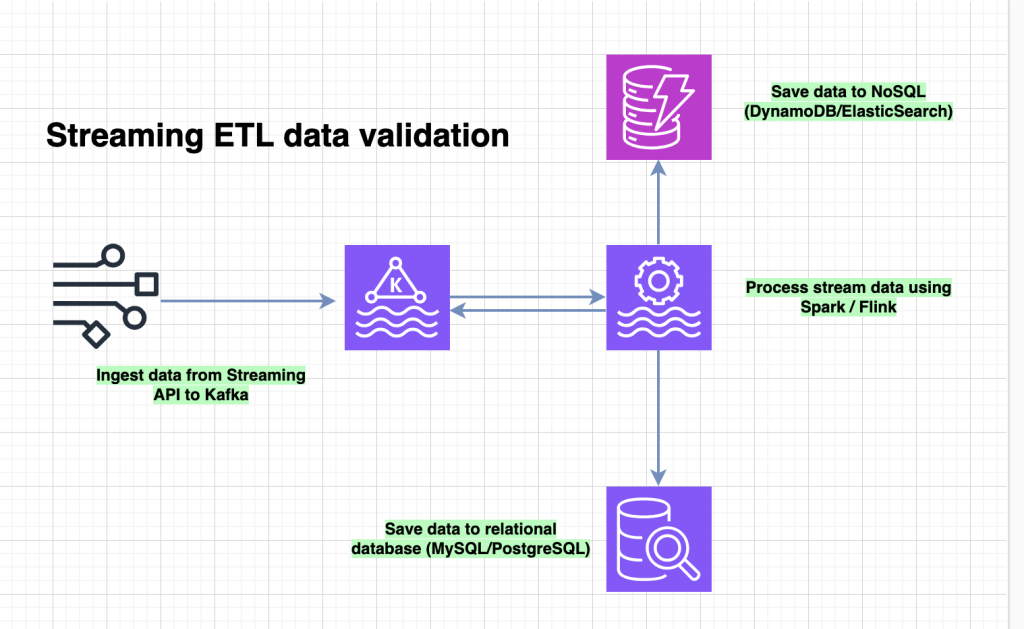
I will use companies house data to show how to validate streaming data.
Steps
- ingest data from kafka into micro batches – (bounded)
address = (spark
.readStream
.format("kafka")
.option("kafka.request.timeout.ms",120000)
.option("kafka.bootstrap.servers", hosts)
.option("subscribe", topic)
.option("startingOffsets", "latest")
.load()
)- transform dataframe – deserialise kafka payload and apply validation check
# validation check
def data_validation_check(df):
# check for valid UK postcode
postcode_regex = "^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|"\
"(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?))))\\s?[0-9][A-Za-z]{2})$"
issue_col = "qa_issues"
df1 = df.withColumn(issue_col,F.lit(""))
# postcode
postcode_cols = [
"postal_code",
]
check_columns = dc.column_iterator(postcode_cols, df1, issue_col)
df1 = check_columns(dc.check_postcode)(output_string="check_postcode")
# warn if col is null
not_null_cols = [
"address_line_1",
"postal_code",
]
check_columns = dc.column_iterator(not_null_cols, df1, issue_col)
df1 = check_columns(dc.check_not_null)(output_string="check_not_null")
# address fields can contain valid postcode - we need to identfy those rows
address_cols = [
'address_line_1',
'address_line_2',
]
for col in address_cols:
check_col = ~(df1[col].rlike(postcode_regex) & df1[col].isNotNull())
df1 = (df1.withColumn(issue_col,dc.add_to_string_col(
df1[issue_col], f"check_postcode_in_address({col})",check_col))
)
return df1
#
# convert key, value field values to string
#
df = df.selectExpr("topic","partition","offset","timestamp","timestampType","CAST(key AS STRING)", "CAST(value AS STRING)")
print("Schema....\n",df.printSchema())
# deserialize
df1, schema = deserialize_payload(spark,df,schema)
print("Hello ",df1.printSchema())
# extract data related to address
df_address = (df1.select('*','payload.data.company_number',
'payload.data.company_name',
'payload.data.sic_codes',
'payload.data.registered_office_address.*',
*[F.col('payload.data.service_address.'+c).alias('service_'+c) for c in df1.select('payload.data.service_address.*').columns],
*[F.col('payload.event.'+c).alias('event_'+c) for c in df1.select('payload.event.*').columns]
).drop('payload')
)
df_address = df_address.withColumn("sic_codes",F.concat_ws(",",F.col('sic_codes')))
df_address = data_validation_check(df_address)- save data (wtiteStrem)
#kafka
CHECKPOINT_LOCATION = "/data/checkpoint/kafka"
query1 = (df_address.filter(df_address.key.isNotNull())
.writeStream.trigger(processingTime="5 minutes")
.outputMode("update")
.queryName("address")
.format("kafka")
.option("topic", topic)
.option("kafka.batach.size", 5000)
.option("kafka.request.timeout.ms",120000)
.option("kafka.bootstrap.servers", hosts)
.option("checkpointLocation", CHECKPOINT_LOCATION)
.start()
)
#console
query2 = (df_address.writeStream
.trigger(processingTime="5 minutes")
.queryName("companies")
.outputMode("update")
.format("console")
.start()
)
#block
query2.awaitTermination()Verify data
Run python script
spark-submit --packages "org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.0" ch_address.pyChecking number of records in ch-address kafka topic – ch-address
pi@ellodata03:~ $ ./number_of_records_topic.sh ch-address
Number of records in topic ch-address: 0
pi@ellodata03:~ $ ./number_of_records_topic.sh companies
Number of records in topic companies: 2326
pi@ellodata03:~ $ ./number_of_records_topic.sh companies
Number of records in topic companies: 2368
pi@ellodata03:~ $ ./number_of_records_topic.sh ch-address
Number of records in topic ch-address: 123
# ch_address dataframe schema
df_address
root
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
|-- key: string (nullable = true)
|-- company_number: string (nullable = true)
|-- company_name: string (nullable = true)
|-- sic_codes: string (nullable = false)
|-- address_line_1: string (nullable = true)
|-- address_line_2: string (nullable = true)
|-- care_of: string (nullable = true)
|-- country: string (nullable = true)
|-- locality: string (nullable = true)
|-- po_box: string (nullable = true)
|-- postal_code: string (nullable = true)
|-- region: string (nullable = true)
|-- service_address_line_1: string (nullable = true)
|-- service_address_line_2: string (nullable = true)
|-- service_country: string (nullable = true)
|-- service_locality: string (nullable = true)
|-- service_postal_code: string (nullable = true)
|-- service_region: string (nullable = true)
|-- event_published_at: string (nullable = true)
|-- event_timepoint: long (nullable = true)
|-- event_type: string (nullable = true)
|-- qa_issues: string (nullable = false)