I asked a question to Amazon Q “How to use QuickSight Amazon Q for customer segmentation?” and also asked several follow up questions. To get the scripts working it needed little of bit tweaking. In most cases results were quite accurate and are listed below:
Using sample date
Certainly! I can help you create a sample dataset in Python that includes attributes useful for customer segmentation. This dataset will include demographics, purchase history, and behavior patterns. Here’s a Python script to generate this sample data:
Generated Python Script
import pandas as pd
import numpy as np
from faker import Faker
import random
from datetime import datetime, timedelta
# Initialize Faker for UK locale
fake = Faker('en_GB')
# Set random seed for reproducibility
np.random.seed(42)
random.seed(42)
# Number of customers
n_customers = 1000
# Generate customer data
data = {
'customer_id': range(1, n_customers + 1),
'age': np.random.randint(18, 80, n_customers),
'gender': np.random.choice(['Male', 'Female', 'Other'], n_customers),
'income': np.random.randint(20000, 200000, n_customers),
'location': [fake.city() for _ in range(n_customers)],
'postcode': [fake.postcode() for _ in range(n_customers)],
'job': [fake.job() for _ in range(n_customers)],
'marital_status': np.random.choice(['Single', 'Married', 'Divorced'], n_customers),
'education': np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], n_customers),
'total_purchases': np.random.randint(1, 100, n_customers),
'avg_order_value': np.random.uniform(50, 500, n_customers).round(2),
'favorite_category': np.random.choice(['Electronics', 'Clothing', 'Books', 'Home & Garden', 'Sports'], n_customers),
#'last_purchase_date': [fake.date_between(start_date='-1y', end_date='today').strftime('%Y-%m-%d') for _ in range(n_customers)],
'last_purchase_date': [fake.date_between(start_date='-1y', end_date='today') for _ in range(n_customers)],
'website_visits_per_month': np.random.randint(1, 30, n_customers),
'avg_time_spent_min': np.random.randint(1, 60, n_customers),
'email_engagement_rate': np.random.uniform(0, 1, n_customers).round(2),
'social_media_follower': np.random.choice([True, False], n_customers),
'loyalty_program_member': np.random.choice([True, False], n_customers),
'preferred_payment_method': np.random.choice(['Credit Card', 'PayPal', 'Bank Transfer', 'Cash'], n_customers),
}
# Create DataFrame
df = pd.DataFrame(data)
# Convert last_purchase_date to datetime
df['last_purchase_date'] = pd.to_datetime(df['last_purchase_date'])
# Calculate customer lifetime value (a simple example)
df['customer_lifetime_value'] = (df['total_purchases'] * df['avg_order_value']).round(2)
# Calculate recency (days since last purchase)
df['recency'] = (pd.Timestamp.now().floor('D') - df['last_purchase_date']).dt.days
# Print first few rows
print(df.head())
# Save to CSV
df.to_csv('customer_segmentation_data.csv', index=False)This script will generate a CSV file with customer data including all the fields we discussed earlier.
After running this script:
- The generated CSV file will contain customer data with properly formatted dates.
- Upload this CSV file to your preferred AWS data source (like S3 or RDS).
- In QuickSight, create a new dataset using this uploaded file.
- When defining the dataset in QuickSight, ensure that the ‘last_purchase_date’ field is recognized as a date type. If it’s not, you may need to change the data type for this column in QuickSight.
Once your data is in QuickSight, you can use Amazon Q to analyze it and create customer segments. For example, you could ask:
- “What’s the average recency for customers in each income bracket?”
- “Show me the distribution of customer lifetime value by education level”
- “Which postcodes have the highest concentration of loyalty program members?”
These analyses can provide valuable insights for your customer segmentation strategies. Remember to combine these data-driven insights with your business knowledge for the most effective segmentation approach.
Generated code for uploading customer segmentation data into S3 bucket and RDS PostgreSQL database
import boto3
import pandas as pd
import psycopg2
from io import StringIO
# AWS S3 configuration
S3_BUCKET_NAME = 'your-s3-bucket-name'
S3_FILE_NAME = 'customer_segmentation_data.csv'
# RDS PostgreSQL configuration
RDS_HOST = 'localhost'
RDS_PORT = 5432
RDS_DATABASE = 'ellodb'
RDS_USER = 'postgres'
RDS_PASSWORD = 'password'
# Read the CSV file
df = pd.read_csv('customer_segmentation_data.csv')
# Upload to S3
def upload_to_s3(df, bucket_name, file_name):
s3_client = boto3.client('s3')
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
s3_client.put_object(Bucket=bucket_name, Key=file_name, Body=csv_buffer.getvalue())
print(f"Data uploaded to S3 bucket: {bucket_name}/{file_name}")
# Upload to RDS PostgreSQL
def upload_to_rds(df, host, port, database, user, password):
conn = psycopg2.connect(
host=host,
port=port,
database=database,
user=user,
password=password
)
cursor = conn.cursor()
# Create table
create_table_query = """
CREATE TABLE IF NOT EXISTS customer_segmentation (
customer_id INTEGER PRIMARY KEY,
age INTEGER,
gender VARCHAR(10),
income INTEGER,
location VARCHAR(100),
postcode VARCHAR(10),
job VARCHAR(100),
marital_status VARCHAR(20),
education VARCHAR(20),
total_purchases INTEGER,
avg_order_value FLOAT,
favorite_category VARCHAR(50),
last_purchase_date DATE,
website_visits_per_month INTEGER,
avg_time_spent_min INTEGER,
email_engagement_rate FLOAT,
social_media_follower BOOLEAN,
loyalty_program_member BOOLEAN,
preferred_payment_method VARCHAR(20),
customer_lifetime_value FLOAT,
recency INTEGER
)
"""
cursor.execute(create_table_query)
conn.commit()
# Insert data
for _, row in df.iterrows():
insert_query = """
INSERT INTO customer_segmentation (
customer_id, age, gender, income, location, postcode, job, marital_status, education,
total_purchases, avg_order_value, favorite_category, last_purchase_date,
website_visits_per_month, avg_time_spent_min, email_engagement_rate,
social_media_follower, loyalty_program_member, preferred_payment_method,
customer_lifetime_value, recency
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(insert_query, tuple(row))
conn.commit()
cursor.close()
conn.close()
print("Data uploaded to RDS PostgreSQL database")
# Execute uploads
#upload_to_s3(df, S3_BUCKET_NAME, S3_FILE_NAME)
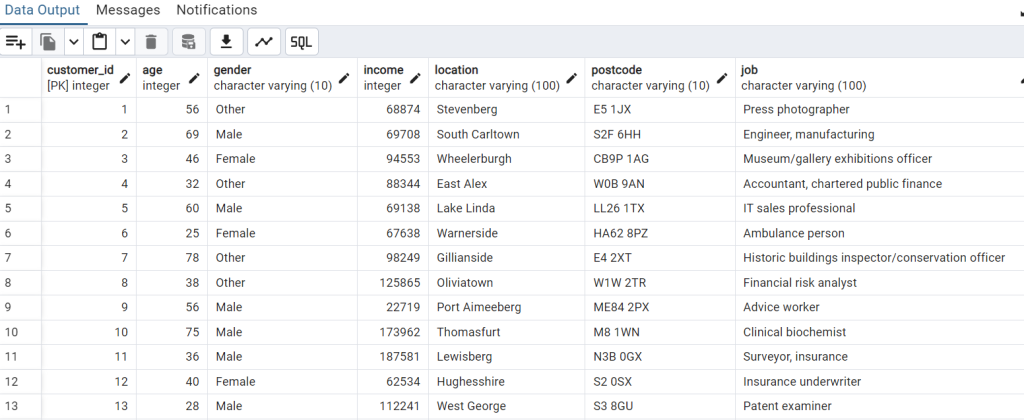
upload_to_rds(df, RDS_HOST, RDS_PORT, RDS_DATABASE, RDS_USER, RDS_PASSWORD)Screenshot of fake data
Using Amazon QuickSight
I am assuming your user account is linked with QuickSight and using the appropriate role to use Amazon Q.
You may have to upgrade user roles to Reader Pro, Author Pro, or Admin Pro to take advantage of the generative AI capabilities of Amazon Q in QuickSight.
I have created datasource by uploading “customer_segmentation_data.csv” file.
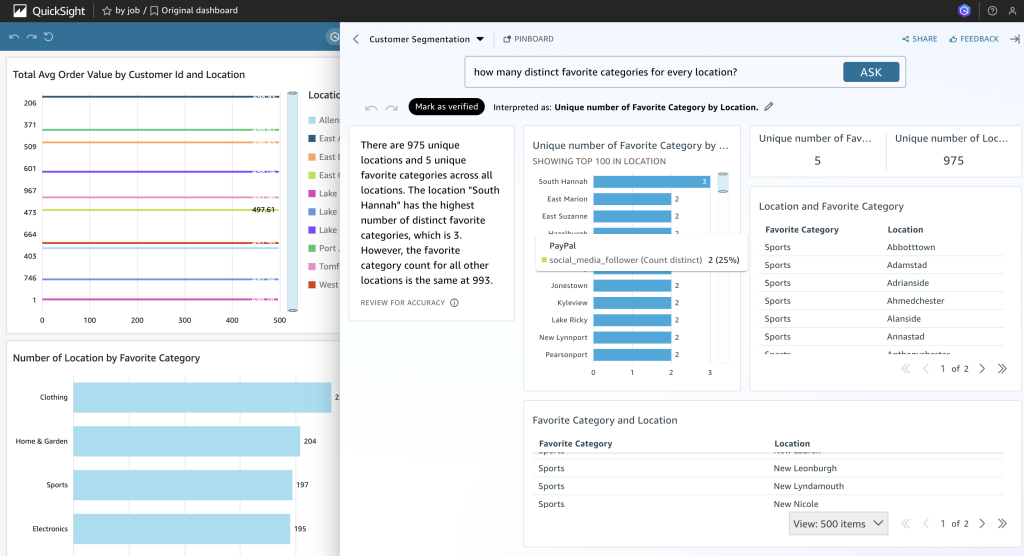
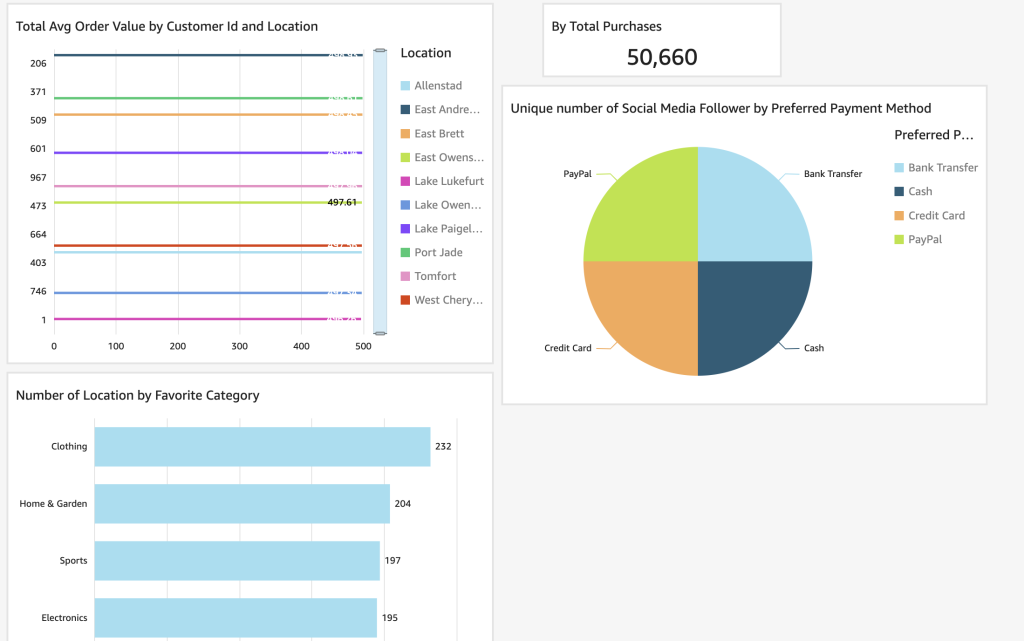
Example of Dashbaord
Rewrite python script using SqlAlcemey
I asked
“rewrite the script for large datasets, using batch processing to avoid memory issues.”
Response from Amazon Q
Certainly! I’ll rewrite the script to handle large datasets using batch processing. This approach will help avoid memory issues when dealing with a large number of records. We’ll use pandas to read the CSV file in chunks and process each chunk separately. Here’s the updated script:
import pandas as pd from sqlalchemy import create_engine, Column, Integer, String, Float, Boolean, Date from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker from sqlalchemy.dialects.postgresql import insert from sqlalchemy.sql import text # RDS PostgreSQL configuration RDS_HOST = 'your-rds-endpoint' RDS_PORT = 5432 RDS_DATABASE = 'your-database-name' RDS_USER = 'your-username' RDS_PASSWORD = 'your-password' # SQLAlchemy setup DATABASE_URI = f"postgresql://{RDS_USER}:{RDS_PASSWORD}@{RDS_HOST}:{RDS_PORT}/{RDS_DATABASE}" engine = create_engine(DATABASE_URI) Base = declarative_base() # Define the Customer model class Customer(Base): __tablename__ = 'customer_segmentation' customer_id = Column(Integer, primary_key=True) age = Column(Integer) gender = Column(String(10)) income = Column(Integer) location = Column(String(100)) postcode = Column(String(10)) job = Column(String(100)) marital_status = Column(String(20)) education = Column(String(20)) total_purchases = Column(Integer) avg_order_value = Column(Float) favorite_category = Column(String(50)) last_purchase_date = Column(Date) website_visits_per_month = Column(Integer) avg_time_spent_min = Column(Integer) email_engagement_rate = Column(Float) social_media_follower = Column(Boolean) loyalty_program_member = Column(Boolean) preferred_payment_method = Column(String(20)) customer_lifetime_value = Column(Float) recency = Column(Integer) # Ensure the table exists Base.metadata.create_all(engine) def merge_and_update_data(new_data_file, chunk_size=10000): # Create a session Session = sessionmaker(bind=engine) session = Session() try: # Read and process the CSV file in chunks for chunk in pd.read_csv(new_data_file, chunksize=chunk_size): # Convert date columns to datetime # Prepare the data for upsert data_to_upsert = chunk.to_dict(orient='records') # Perform the upsert operation stmt = insert(Customer).values(data_to_upsert) stmt = stmt.on_conflict_do_update( index_elements=['customer_id'], set_={c.key: c for c in stmt.excluded if c.key != 'customer_id'} ) session.execute(stmt) session.commit() print(f"Processed {len(chunk)} records") print("Data merge and update completed successfully") except Exception as e: session.rollback() print(f"An error occurred: {e}") finally: session.close() def optimize_table(): with engine.connect() as connection: connection.execute(text("VACUUM ANALYZE customer_segmentation;")) print("Table optimized") # Example usage merge_and_update_data('new_customer_data.csv', chunk_size=10000) optimize_table()Key changes and features in this updated script:
- Batch Processing : The
merge_and_update_datafunction now usespd.read_csvwith thechunksizeparameter. This allows it to read the CSV file in chunks, processing a specified number of rows at a time.- Configurable Chunk Size : The
chunk_sizeparameter (default 10,000) allows you to adjust the number of records processed in each batch based on your system’s memory capacity and the size of your dataset.- Progress Reporting : The script prints the number of records processed after each chunk, giving you visibility into the progress.
- Table Optimization : After the merge and update process, an
optimize_tablefunction is called. This function runs aVACUUM ANALYZEcommand on the table, which can help improve query performance after large data modifications.To use this script:
- Replace the placeholder values in the RDS configuration section with your actual database details.
- Ensure you have the required Python libraries installed:
pip install pandas sqlalchemy psycopg2-binaryCopyInsert at cursortext- Prepare your new customer data in a CSV file (e.g., ‘new_customer_data.csv’). This file should have the same structure as your original customer_segmentation_data.
- Run the script, optionally specifying a custom chunk size:
merge_and_update_data('path_to_your_new_customer_data.csv', chunk_size=20000)CopyInsert at cursorpythonThis script offers several advantages for handling large datasets:
- Memory Efficiency : By processing the data in chunks, it avoids loading the entire dataset into memory at once.
- Scalability : It can handle very large CSV files, limited only by disk space rather than RAM.
- Progress Tracking : You can monitor the progress as it processes each chunk.
- Database Optimization : The final step optimizes the table for better query performance.
Additional considerations:
- Adjust the
chunk_sizebased on your system’s capabilities and the size of your dataset. A larger chunk size may be faster but will require more memory.- For extremely large datasets, you might want to add more granular error handling and logging.
- Consider adding a way to resume processing from where it left off in case of interruption during a long-running job.
- Always backup your data before performing large merge operations, especially in production environments.
After running this script, your ‘customer_segmentation’ table in the RDS PostgreSQL database will be updated with the merged data, efficiently handling large datasets. You can then use this updated and optimized dataset in QuickSight for your customer segmentation analysis.
Ticket sales analysis and trends
I tried “How to use Quicksight Amazon Q for ticket sales and trends using fake data?“
Certainly! I’ll guide you through the process of using QuickSight Amazon Q for analyzing ticket sales and trends using fake data. We’ll start by creating a sample dataset, importing it into QuickSight, and then using Amazon Q to analyze the data. [1]
Step 1: Create a sample dataset
First, let’s create a Python script to generate fake ticket sales data:
import pandas as pd import numpy as np from faker import Faker from datetime import datetime, timedelta fake = Faker() # Set random seed for reproducibility np.random.seed(42) # Generate data n_records = 10000 start_date = datetime(2023, 1, 1) end_date = datetime(2023, 12, 31) data = { 'date': [fake.date_between(start_date=start_date, end_date=end_date) for _ in range(n_records)], 'event_name': [fake.catch_phrase() for _ in range(n_records)], 'venue': [fake.city() for _ in range(n_records)], 'ticket_type': np.random.choice(['General', 'VIP', 'Early Bird', 'Group'], n_records), 'price': np.random.uniform(20, 500, n_records).round(2), 'quantity_sold': np.random.randint(1, 100, n_records), 'customer_age': np.random.randint(18, 75, n_records), 'customer_gender': np.random.choice(['Male', 'Female', 'Other'], n_records), 'promotion_code': np.random.choice([None, 'SUMMER10', 'EARLYBIRD', 'GROUPDEAL'], n_records) } df = pd.DataFrame(data) df['total_sales'] = df['price'] * df['quantity_sold'] df['day_of_week'] = df['date'].dt.day_name() df['month'] = df['date'].dt.month_name() # Save to CSV df.to_csv('ticket_sales_data.csv', index=False) print("Data saved to 'ticket_sales_data.csv'")
This script creates a CSV file with fake ticket sales data, including date, event name, venue, ticket type, price, quantity sold, customer demographics, and promotional information.
Step 2: Import data into QuickSight [2]
- Log in to your AWS account and navigate to QuickSight. [3]
- Click on “Datasets” in the left sidebar, then “New dataset”.
- Choose “Upload a file” and select the ‘ticket_sales_data.csv’ file you created.
- Review the data and click “Publish & visualize”.
Step 3: Using Amazon Q for analysis
Now that your data is in QuickSight, you can use Amazon Q to analyze ticket sales and trends. Here are some example questions you can ask Amazon Q:
- “Show me the total ticket sales trend over time” Amazon Q might create a line chart showing daily or monthly total sales.
- “What are the top 5 best-selling events?” This could result in a bar chart of the events with the highest total sales.
- “Compare ticket sales by ticket type” Amazon Q might generate a pie chart or stacked bar chart showing the distribution of sales across different ticket types.
- “Analyze the correlation between ticket price and quantity sold” This could produce a scatter plot with price on one axis and quantity sold on the other.
- “Show me the sales performance by day of the week” Amazon Q might create a bar chart showing total sales for each day of the week.
- “What’s the average customer age for VIP tickets compared to General tickets?” This could result in a comparison chart showing the average age for different ticket types.
- “How effective are our promotion codes in driving sales?” Amazon Q might generate a comparison of total sales with and without promotion codes.
- “Which venues have the highest average ticket prices?” This could produce a ranked list or bar chart of venues by average ticket price.
- “Show me the monthly sales trend for each ticket type” Amazon Q might create a stacked area chart showing how sales of different ticket types change over months.
- “What’s the gender distribution of our customers for different event types?” This could result in a series of pie charts or a stacked bar chart showing gender distribution across events.
To use Amazon Q in QuickSight:
- In your QuickSight analysis, click on the “Ask a question” button (which looks like a chat bubble) in the top right corner.
- Type in your question or request in natural language.
- Amazon Q will generate a visualization based on your question. You can then refine the question or ask follow-up questions to dive deeper into the data.
Remember, Amazon Q’s strength lies in its ability to understand natural language queries, so feel free to ask questions as you would to a human analyst. You can also use Amazon Q to help interpret the results, asking questions like “What insights can you draw from this trend?” or “What factors might be contributing to this pattern?”
By leveraging Amazon Q with this fake ticket sales data, you can quickly gain insights into sales trends, popular events, pricing strategies, and customer demographics, all of which can inform decision-making in a real-world scenario.
Sources
[1] Starting an analysis in Amazon QuickSight – Amazon QuickSight