I use Google Colab for my development work. I have setup a Kafka server on my local machine (RapsberryPi). The task in hand to use PySpark to read and write data. You can use Batch or Streaming query.
Spark has an extensive documentation at their website under the heading – Structured Streaming + Kafka Integration Guide.
Read data from Kafka – Batch
Create a dataframe using spark.read.format(“kafka”):
# Subscribe to multiple topics, specifying explicit Kafka offsets
df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") \
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")Create a dataframe for streaming query
Use spark.readstream.format(“kafka”) for streaming query.
# Subscribe to 1 topic, with headers
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.option("includeHeaders", "true") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "headers")Use case – Kafka batch queries for storing and handing web server access log files
I want to store web server access log files in Kafka and read data from it. Here are the steps:
- ingest server log files and create a dataframe
- send data in chunks to Kafka
- verify data is stored in Kafka as expected
Prerequisites
- Kafka server is up and running and a topic is available for storing and reading
- a dataframe containing web server access logs data
Ingest server log files and create a dataframe
I have a compressed file containing log files – /content/pi-logs-01.tar.gz/. Upload it to Google Colab instance, used tar xvf command to save them to a folder and used spark.read.option(‘delimiter’,’ ‘).csv(“/content/var/log/apache2/”) to create dataframe.
# create dataframe
df = spark.read.option('delimiter',' ').csv("/content/var/log/apache2/")
from pyspark.sql import functions as F
# dd/MMM/yyyy:hh:mm:ss
df = df.select(
df._c0.alias('ipaddress'),
F.regexp_extract(df._c3, "\[([^\]]+)", 1).alias('datetime'),
F.split(df._c5,' ')[0].alias('method'),
F.split(df._c5,' ')[1].alias('endpoint'),
F.split(df._c5,' ')[2].alias('protocol'),
df._c6.alias('responsecode'),
df._c7.alias('contentsize'),
df._c8.alias('referer'),
df._c9.alias('useragent'),
)
Send data in chunks to Kafka
Split dataframe into smaller chunks and write them to kafka as batch query
# function to write data to kafka
def kafka_write_data(df,hosts,topic):
(df
.select(F.monotonically_increasing_id().cast('string').alias('key'),F.to_json(F.struct([F.col(c).alias(c) for c in df.columns])).alias("value"))
.write
.format("kafka")
.option("kafka.bootstrap.servers", hosts)
.option("topic", topic)
.save()
)
return True
# save data in chunks
# Define the number of splits you want
n_splits = 4
# Calculate count of each dataframe rows
each_len = df.count() // n_splits
# Create a copy of original dataframe
copy_df = df
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# View the dataframe
temp_df.show(10,truncate=False)
kafka_write_data(temp_df,"broadoakdata.uk:9092","apache2")
# Increment the split number
i += 1Verify data in Kafka
Get few records from Kafka using startingOffsets and endingOffsets option of Kafka read command.
# only 1 partition
def kafka_read_data(spark,hosts,topic,topic_start,tpoic_end):
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", hosts)
.option("subscribe", topic)
.option("startingOffsets", topic_start)
.option("endingOffsets", topic_end)
.load()
)
return df
# set hosts and topic
hosts = "broadoakdata.uk:9092"
topic = "apache2"
topic_start = '{"'+topic+'":{"0":81147}}'
topic_end = '{"'+topic+'":{"0":91147}}'
# get data
df_read = kafka_read_data(spark,hosts,topic,topic_start,topic_end)
df_read = df_readselectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
df_read.show(20,truncate=False)Screenshot

Data analysis – seeking suspicious calls to my web server
It seems my web server was getting unwanted requests from number of clients. In particular they were calling ‘xmlrpc.php’ via POST method. I needed to find how many calls per day.
# filter only endpoint=='/xmlrpc.php'
codes_by_date_sorted_df = (df.filter(df.endpoint=='/xmlrpc.php')
.groupBy(F.dayofmonth(F.to_date(F.substring(F.col('datetime'),0,11),'dd/MMM/yyyy')).alias('day'))
.count()
.sort("day"))
codes_by_date_sorted_pd_df = codes_by_date_sorted_df.toPandas()
codes_by_date_sorted_pd_dfVisualise the finding
import plotly.express as px
px.bar(
codes_by_date_sorted_pd_df,
x="day",
color="day",
y="count",
barmode='group'
)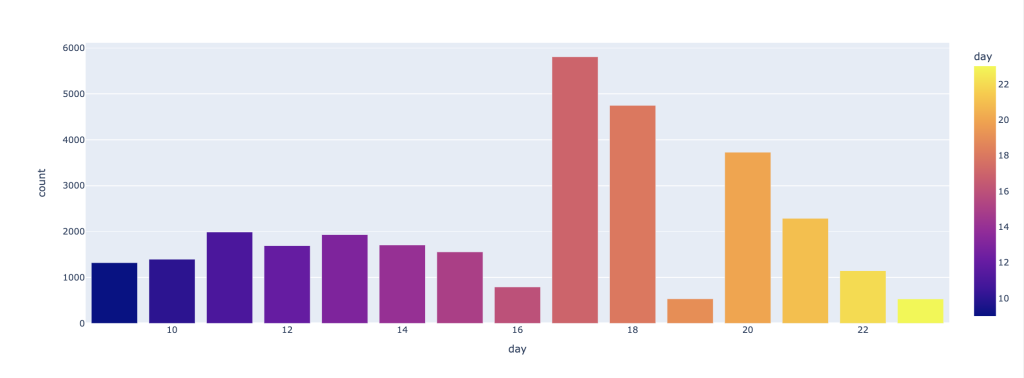
Terrible finding! I had to move my site to SiteGround – https://broadoakdata.uk/